PPL's Main Features at a Glance
General Properties
-
Object-oriented with some functional extensions
PPL is primarily an object-oriented language that supports typical OO-features such as multiple type inheritance, data encapsulation and polymorphism. It also supports some techniques typically (but not exclusively) found in functional programming languages such as first-class functions, lambdas/closures, sequential and parallel streams, immutability by default, and type inference.
-
Designed to find bugs quickly
The main design goal of PPL is to eliminate whole classes of bugs, and to find remaining bugs as quickly as possible (see list of features below).
-
High level
PPL is a high level language.
It is not the best option for writing low-level code applications, such as an OS kernel, a video game or fast number crunching programs. However, low level code (C, assembler, etc) can be called from PPL through Java's JNI (Java Native Interface).
-
JVM language
When you build a PPL application, PPL source code is converted into Java binary code (.jar files).
Therefore PPL applications run on any system that supports a Java Virtual Machine (JVM), such as MAC OS, Linux/Unix and Windows.
-
Simple but not simplistic
Instead of providing a maximum of programming techniques, PPL aims to support only a minimum of selected and proven (or innovative) techniques that support software reliability (less bugs), work seamlessly together, evolve together and are easy to understand and use.
Complexity at the language level is kept at a minimum.
Joshua Bloch once gave the following excellent advice:
"APIs should be easy to use and hard to misuse. It should be easy to do simple things; possible to do complex things; and impossible, or at least difficult, to do wrong things."
The same should be true for PPL.
Features for More Reliable Code
-
Compile-time null-safety
PPL code doesn't throw null pointer errors/exceptions at run-time.
Null-safety is natively built into the language. The compiler ensures that object references that could point to
nullat runtime are checked fornull, before its features can be accessed (e.g.order.delivery_date). There are also special instructions and operators for writing null-safe code.As a result the most common bug in non-null-safe languages (i.e.
NullPointerExceptionin Java orNullReferenceExceptionin C#) is eliminated. -
Design by Contract
Design by Contract is one of the most effective techniques for automatic bug detection early at run-time.
Design by Contract prevents object construction with invalid data and it protects functions against invalid input/output arguments.
-
Integrated unit testing
Unit testing is a standard feature in PPL and easy to use (no setup or configuration needed).
-
Generic type parameters
Generic types increase type safety and help to detect bugs at compile-time.
In PPL there is no type erasure at run-time. Generic parameters (e.g. the type of objects in a list) can be programmaticaly retrieved at run-time.
Type compatibility of generic types is handled in a type-safe way by the compiler.
-
Compiled language
A compiler is able to find many bugs and therefore contributes to more reliable software.
At the time of writing, the PPL compiler detects 379 different kinds of semantic bugs (besides syntax and grammar errors) in the source code, and this number is meant to increase in the future.
For example, if we test the type of an object, the compiler will ensure we didn't forget a sub-type. If we test the value of an enumerated type, the compiler also ensures that all possible values are covered. These kind of checks are especially useful in big applications with lots of refactorings and many programmers working on the same codebase.
Another advantage is that compiled code runs faster than interpreted code.
Incremental compiling is also implemented in PPL. The time needed to re-compile modified source code is kept to a minimum.
-
Very defensive APIs
All Fail-fast! features are consistently applied in PPL's standard libraries.
This shields library components from some illegal (or unintended) usages and therefore helps to detect bugs early.
-
No error-prone features
Error-prone programming techniques are omitted in PPL as far as possible.
For example, there are:
- no primitive types or arrays - just pure objects that behave the same in all situations
- no automatic type casts, conversions or coercions
- no truthy or falsy values (e.g
"",0andnullare all equal tofalse) - no silent arithmetic overflow errors
- no data/method/variable overloading or hiding/shadowing
- no superfluous functions in the root type that can lead to subtle bugs if not correctly implemented in all child types (e.g.
equals,compare,hashcode,clone). The root type in PPL has only one function:to_string - no 'undefined behavior' (such as in C/C++)
-
Static typing
Static typing
- helps to find certain bugs at compile-time
- improves API understandability
- increases runtime efficiency and
- supports more sophisticated features in tools (e.g. better code completion in an IDE)
Therefore PPL is statically typed.
Type inference is supported for local script constants/variables.
However, dynamic typing is supported through a built-in reflection mechanism. For example, at run-time you could:
- read the name of an object attribute (field) from a configuration file and then programmatically change the corresponding attribute value of an object - thereby creating a (recoverable) run-time error if such an attribute doesn't exist in the given object or if the new value is of the wrong type
- read a source code expression or script from a database field and then evaluate the expression or execute the script
- write code that writes code and then executes that code!
-
Semantic typing
Semantic typing ensures that two objects are type-incompatible, although they contain data of the same type. For example, type 'temperature_in_celsius' is not compatible to 'temperature_in_fahrenheit', although the values of both types are integers.
-
Feature redefinition in child types
PPL supports covariant and contravariant feature redefinition in child types.
This technique is often used to define child types with more restrictive data checks. For example, attribute 'identifier' of type 'book' which inherits from type 'product' must be a valid ISBN number, instead of an unrestricted string.
-
Union types
Union types (also called sum-types) enable you to state that an object can have one type among a set of different types.
Example: the output of function
read_string_from_fileis of typestring or error. You can then use acase type ofinstruction to test the return value's type and take appropriate action, depending on whether the function returns astringor anerror. -
Objects are immutable by default
Immutable objects don't have state transitions. Therefore they:
- are easy to understand and use
- are less error-prone than mutable objects (for example only immutable objects can be used as keys in hash maps - no need to worry about very nasty behavior in multi-threaded applications)
- don't need synchronisation
- can freely be shared in multi-threaded, multi-processor and cloud environments
Therefore objects in PPL are immutable by default. For example, all PPL standard libraries return immutable lists and maps, except in very rare cases where the context requires a mutable object.
-
No resource leaks
The 'use resource' instruction ensures that system resources (e.g. files, database and network connections) are automatically closed at the end, even if a program error (exception) occurs between opening and closing the resource.
Features for More Productivity
-
Full integration with Java (data, code and JVM)
PPL and Java code can be mixed and in-memory data can be exchanged between PPL and Java.
You can embed and use anyone of the huge set of available Java packages (.jar files) and Java source code files (.java files) in a PPL project.
-
Portable (MAC OS X/Linux/Unix/Windows)
Because PPL is a JVM language the Java slogan 'write once, run anywhere' also holds for PPL.
A team can develop applications on (a mixture of) systems that support Java (e.g. MAC OS, Linux/Unix, Windows) and then run the application on any (other) platforms that support Java.
PPL takes care of operating system differences such as line feeds (LF or CRLF) and directory separators (/ or \).
-
Default input argument values
You can define default values for object attributes and input arguments.
This is easier to use, less error-prone and more flexible than method overloading.
-
Multiple output arguments
PPL functions can have zero, one or more output arguments.
You don't need to create a special type to return multiple values, or to use an input value as a container for returning an output value.
-
Single file scripting
You can create single executable source code files composed of PPL source code and (optionally) embedded Java source code.
This is very useful for writing small utilities or for just testing some instructions without the need to create a PPL project composed of multiple files.
-
No getters, setters and imports to write
You don't need to write getters and setters (i.e. methods to get and set object values), except in rare cases where you want a specific implementation.
You also don't need to write and maintain
import / usingstatements at the beginning of source code files. -
Type inference
Type inference is supported for local script constants and variables.
-
Visual Object Explorer
Any object existing at runtime can be shown in a graphical user interface. The GUI automatically selects the right widget for each object. For example, collections (e.g.
list<book>) are shown in a table with one column per object attribute (e.g. columnsid,title, etc.). The table provides useful features such as sorting, filtering, searching, printing, exporting to text files, etc. Tree structures are shown in an expandable tree view. Other objects are shown in a form with 1 field per object attribute. In case of complex objects you can drill down to any level of nested attributes.Any object can be visualized by just coding
object_GUI.show ( object )
Here is a simple example of a
bookobject displayed by PPL's integrated Visual Object Explorer: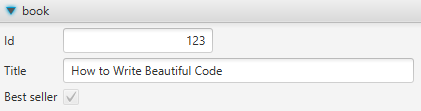
-
debuginstructionYou can set a breakpoint anywhere in the source code by simply inserting a
debuginstruction. Whendebugis encountered at runtime, program execution stops temporarily. A GUI is opened and displays the calling stack, as well as the state of all object references (input/output arguments, constants, variables and type attributes). You can then inspect any object with the previously mentioned Visual Object Explorer.